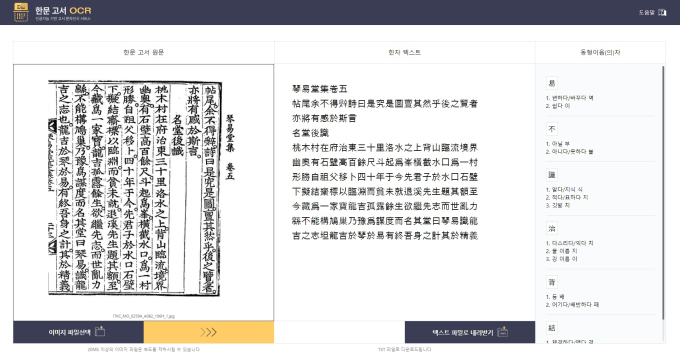
진흥원에 따르면 올해 ㈜누리 IDT, ㈜NHN다이퀘스트, ㈜에프아이솔루션과 함께 1차 년도 사업을 완료했다. 유교책판의 활자를 영인한 고서의 한자 인식률 70%를 목표로 시작했던 1차 사업은 현재 약 80%의 정확도로 문자를 인식하는 수준에 이르렀다.
이 결과는 현재 최종 품질 검증을 거쳐 AI-Hub를 통해 공개할 예정이다.
이번 ‘한자 인식 OCR 인공지능 모델 개발’은 인공지능(AI)이 가진 딥러닝(Deep Learnimg) 기술이 적극 차용됐다. 고서 속에 비교적 정자체로 기록된 한자의 다양한 이미지를 컴퓨터 텍스트 기호인 유니코드로 인식하도록 학습시키는 데이터셋을 구축, 스캔이나 촬영 등을 통해 이미지가 확보된 한자를 텍스트로 인식해 변환할 수 있도록 했다. 이를 위해 고서 전체 이미지에서 한 글자씩 잘라내고(세그멘테이션) 그 글자 이미지를 텍스트로 인식할 수 있도록 치환하는 기술들이 적용됐다.
현재 글자수 기준 1000만 자의 이미지를 입력하고 이를 인공지능이 지속적으로 학습할 수 있도록 했다. 한국국학진흥원은 기존 DB 구축 사업을 통해 확보된 이미지와 이번 사업을 위해 별도로 고해상도의 이미지 스캔을 해둔 결과물을 중심으로 다양한 글자들을 인공지능이 학습할 수 있도록 했다.
해당 사업이 본 궤도에 오르면 일반 사용자들이 유적지 등을 방문했을 때 한자로 기록된 현판이나 문서들을 이미지로 촬영해 한자의 뜻과 의미를 확인할 수 있게 된다. 또 한자 텍스트를 기반으로 개발 중인 자동 번역 시스템과 연계할 때 한국 고전 번역에 획기적인 속도를 기대할 수 있다.
정종섭 한국국학진흥원장은 “산적한 고서들을 활용하기 위한 첫 단계가 디지털화 작업인데, 이번 1년 차 사업만으로도 디지털화 속도가 몇 배 이상 빨라졌다”며 “향후 이미지 인식률을 높일 수 있는 사업을 계속 추진해나갈 것”이라고 말했다.
zebo15@kukinews.com